ترجمة النص العربي إلى مصطلحات عربية للغة الإشارة
ورقة علمية  وصول مفتوح |
متاح بتاريخ:10 ديسمبر, 2024 |
آخر تعديل:10 ديسمبر, 2024
وصول مفتوح |
متاح بتاريخ:10 ديسمبر, 2024 |
آخر تعديل:10 ديسمبر, 2024
الملخص:
تعد لغة الإشارة العربية (ARSL) لغةً يستخدمها مجتمع الصم في جميع أنحاء الدول العربية ولكن عدم إلمام عموم السكان بهذه اللغة غالبًا ما يؤدي إلى العزلة الاجتماعية للصم. وتشكل الاختلافات البنيوية بين لغة الإشارة العربية والعربية المنطوقة تحديات كبيرة للترجمة الآلية. وقد قمنا في هذه الدراسة بتعزيز ترجمة المصطلحات من العربية إلى لغة الإشارة العربية من خلال استخدام تقنيات زيادة البيانات وتوسيع مجموعة البيانات من 600 إلى أكثر من 23328 عينة باستخدام (نماذج تسلسل إلى تسلسل) (Seq2seq) . وقد حقق نهجنا تحسنًا كبيرًا في الأداء مما أدى إلى تحسين درجة معيار التقييم ثنائي اللغة (BLEU) (BLEU) من 11.1٪ في النموذج الأساسي إلى 52.72٪ في مجموعة الاختبار الأصلية. وقد حقق أفضل نموذج نسبة 85.17٪ كدرجة معيار التقييم ثنائي اللغة (BLEU) في اختبار البيانات الجديدة المعززة مما يؤكد فعالية زيادة البيانات في تحسين جودة ترجمة لغة الإشارة العربية.
الكلمات الرئيسية: لغة الإشارة العربية (ARSL)؛ النص المعجمي؛ زيادة البيانات؛ الترجمة الآلية؛ نموذج تسلسل إلى تسلسل (Seq2seq)؛ درجة معيار التقييم ثنائي اللغة (BLEU).
المقدمة
يشكل مجتمع الصم وضعاف السمع العالمي أكثر من 5٪ من سكان العالم ويعتمد هذا المجتمع بشكل كبير على لغات الإشارة للتواصل [1]. إن لغات الإشارة هي لغات غنية بصرية مكانية تستخدم مزيجًا من إيماءات اليد وتعبيرات الوجه وحركات الجسم لنقل المعنى [2]. وتعمل لغة الإشارة العربية على وجه الخصوص كوسيلة أساسية للتواصل لمجتمع الصم في الدول العربية [3]. وعلى الرغم من أهميتها تظل لغة الإشارة العربية غير مألوفة إلى حد كبير للعموم مما يساهم في العزلة الاجتماعية للأفراد الصم. وتتمتع لغة الإشارة العربية بتركيبها النحوي وقواعدها ومعجمها الخاص على عكس اللغة العربية المنطوقة مما يجعل الترجمة بين هاتين اللغتين تحديًا معقدًا.
لقد أرسى تطوير نظام ترجمة آلية قائم على القواعد الدلالية لتحويل النص العربي إلى مصطلحات لغة الإشارة العربية كما هو موضح في [4] أساسًا مهمًا. ومع ذلك بقيت هذه المقاربات مقيدة بتوافر بيانات التدريب وبالقيود المتأصلة في المنهجيات القائمة على القواعد. فقد استند العمل إلى مجموعة بيانات متوازية صغيرة نسبيًا مكونة من 600 جملة عربية مترجمة إلى معجم لغة الإشارة العربية. ورغم كون هذه المجموعة من البيانات مفيدة إلا أنها غير كافية للتعبير عن التنوع الكامل للغة الطبيعية. وقد حقق النظام القائم على القواعد نسبة 35% على معيار التقييم ثنائي اللغة (BLEU) مما يسلط الضوء على التحديات في مجال الحفاظ على المعنى المقصود والبنية النحوية في الترجمة. إن هذه القيود تحد من قابلية التوسع والتكيف لنماذج الترجمة مما يؤدي إلى ترجم منخفضة الدقة.
إن فعالية أنظمة الترجمة الآلية وخاصة تلك المصممة لأزواج لغوية مختلفة مثل اللغة العربية ولغة الإشارة العربية تعتمد بشكل كبير على توافر مجموعات بيانات كبيرة وعالية الجودة. وتسمح مجموعة البيانات الأكثر شمولاً بالحصول على تدريب وتعميم أفضل مما يؤدي إلى ترجم أكثر دقة [5]. كما أظهرت التطورات في معالجة اللغة الطبيعية (NLP) وتقنيات التعلم الآلي مثل نماذج “تسلسل إلى تسلسل” (Seq2seq) إمكانات كبيرة في تحسين دقة الترجمة من خلال تعلم أنماط اللغة المعقدة وعلاقاتها من البيانات المتوفرة بشكل مباشر [6].
يهدف بحثنا إلى معالجة هذه القيود عبر سد الفجوة من خلال الاستفادة من تقنيات زيادة البيانات مثل استبدال الفراغات واستبدال المرادفات وإعادة صياغة الجملة لتوسيع مجموعة البيانات الأصلية من 600 إلى أكثر من 23328 جملة. كما نقوم بتقييم البيانات الناتجة بالاعتماد عل نماذج الترجمة الآلية المتقدمة “تسلسل إلى تسلسل” للغة العربية وتطبيق تقنيات مختلفة في ما يخص حجم البيانات لفحص تأثير حجم مجموعة البيانات على أداء النموذج. إن هذا النهج يجعل البيانات أكثر نفعاً للتدريب ويشمل مجموعة أوسع من التنوع اللغوي.
وتتمثل مساهمة هذا العمل في شقين: (1) نستكشف تقنيات مختلفة لزيادة البيانات لتعزيز حجم مجموعة البيانات وجودة ترجمة لغة الإشارة العربية. (2) نقوم بالتحقيق في نماذج الترجمة الآلية المختلفة “تسلسل إلى تسلسل” ومقارنتها من خلال اختبار أدائها على كل من بيانات الاختبار الأصلية وبيانات الاختبار المعززة.
الأدبيات ذات الصلة
إن ترجمة النص العربي إلى لغة الإشارة العربية أمر ضروري لدمج الأفراد الصم في مجتمعاتهم. ومع ذلك فإن تطوير أنظمة الترجمة الفعّالة يواجه تحديات بسبب ندرة مجموعات النصوص الموازية والتوثيق غير الكامل لقواعد اللغة العربية وبنيتها. ولا تزال الأبحاث في مجال ترجمة لغة الإشارة العربية في مراحلها الأولى مقارنة بلغات الإشارة الأخرى [7] مثل لغة الإشارة الأمريكية (ASL) [8] ولغة الإشارة البريطانية (BSL) [9]. إن العديد من الأنظمة الحالية تعتمد على مقاربات قائمة على القواعد وتتطلب معرفة لغوية واسعة النطاق لربط النص المنطوق أو المكتوب بتعبيرات لغة الإشارة المقابلة.
وفي سياق لغة الإشارة العربية فقد تم استكشاف العديد من المقاربات. حيث ركز [10] على ترجمة الجمل العربية المتعلقة بالصلاة إلى لغة الإشارة العربية باستخدام كتابة الإشارة وهكذا فقد كانت هذه المقاربة محدودة بمجموعاتها الصغيرة وضعف التغطية لهياكل الجمل المختلفة. أم [11] فقد استخدم نهج الترجمة الآلية القائمة على الأمثلة (EBMT) ولكن اعتمادهم على تشكيل جوجل وتشابه الأمثلة أدى إلى ارتفاع معدلات الخطأ. وطور [12] نظامًا قائمًا على القواعد حقق دقة عالية على مستوى الكلمة لكنه لم يعالج بشكل كافٍ الاختلافات النحوية على مستوى الجملة. واستكشف [13] تحويلات بنية الجملة النحوية لكنه اقتصر على هياكل نحوية محددة.
وقد تضمنت التطورات الحديثة تقنيات تعتمد على البيانات مثل الترجمة الآلية الإحصائية (SMT) والترجمة الآلية القائمة على الأمثلة (EBMT) والتي تبدو واعدةً ولكنها تتطلب توافر مجموعات بيانات كبيرة وعالية الجودة. وقد طور [4] نظامًا قائمًا على القواعد لترجمة النص العربي إلى لغة الإشارة العربية باستخدام مجموعة من 600 جملة في مجال الصحة. وفي حين أن نظامهم قد حقق درجة دقة تزيد عن 80٪ فإن حجم مجموعة البيانات المحدود قد حد من قابلية تطبيقه على كامل اللغة وتعميمه على نطاق أوسع.
لقد بُذلت جهود كبيرة لتحسين توافر بيانات لغة الإشارة وشرحها. حيث توفر أداة ترجمة لغة الإشارة “جملة” التي وصفها [14] حلاً قائمًا على الويب إنشاء تعليقات توضيحية للغة الإشارة القطرية (QSL) بنص عربي مكتوب مما يدعم إنشاء تعليقات توضيحية مثل قاموس جملة لغة الإشارة القطرية. وقد وسع [15] هذا العمل من خلال تطوير قاموس جملة (JUMLA-QSL-22) الذي يحتوي على 6300 سجل ممثل بالنصوص الإشارية والترجمة وهوية المؤشر والموقع. وتعد هذه الأدوات ومجموعات البيانات ضرورية لتطوير معالجة لغة الإشارة (SLP) كما تسلط الضوء على الجهود الجارية لإنشاء موارد لغوية أكثر شمولاً للغات الإشارة ذات الصلة باللغة العربية.
لقد تطورت تقنيات الترجمة الآلية (MT) بشكل كبير مع ظهور نماذج الترجمة الآلية العصبية (NMT) مثل بنيات “تسلسل إلى تسلسل” كطرق حديثة في هذا المجال. وقد أظهرت هذه النماذج بما في ذلك الشبكات العصبية المتكررة (RNNs) والهندسة البرمجية القائمة على المحولات قدرة قوية على التعامل مع أزواج اللغات المعقدة من خلال التعلم من كميات هائلة من البيانات لتغطية الأنماط اللغوية والسياقات المختلفة [16]. وفي ما يخص ترجمة لغة الإشارة فقد تم تطبيق هذه النماذج على لغات إشارة أخرى [17] و [18] محققة درجات متفاوتة من النجاح. ويكمن التحدي في تطبيق هذه النماذج بشكل فعال على لغة الإشارة العربية حيث تشكل ندرة البيانات والاختلافات اللغوية عقبات كبيرة. ومع ذلك فإنه يمكن لاستخدام مجموعات البيانات المعززة جنبًا إلى جنب مع نماذج ترجمة لغة الإشارة العربية أن يعزز من دقة الترجمة ويساعد في سد الفجوة بين اللغة العربية المنطوقة ولغة الإشارة العربية.
لقد أظهرنا في عملنا السابق [19] أداء نموذج (AraT5-V2) للترجمة الآلية للغة العربية والتي تم تقييمها باستخدام طرق مختلفة لزيادة البيانات بما في ذلك (BR) و(SP) و(SR). وتظهر النتائج التجريبية أن طريقة (BR) أظهرت أداءً متفوقًا. ويرجع ذلك على الأرجح إلى حجم مجموعة البيانات الأكبر الذي يبلغ 22404 عينة. وعلى النقيض من ذلك فقد أظهرت طريقتا (SP) و(SR) اللتان استخدمتا مجموعات بيانات أصغر حجمًا خسائر أعلى في التحقق ودرجات معيار التقييم ثنائي اللغة (BLEU) أقل بكثير. وقد تم إجراء مزيد من التحليل من خلال الجمع بين طرق الزيادة الثلاثة والمقارنة مع نماذج أخرى بما في ذلك نموذجي (AraT5 Base) و(mT5) الأصليين حيث تفوق نموذج (AraT5 V2) بحصوله على درجة 90.93 على معيار التقييم ثنائي اللغة (BLEU).
وقد قمنا في هذا العمل بتوسيع التحقيق من خلال استخدام تقنيات زيادة البيانات لتوسيع مجموعة البيانات الأصلية إلى أكثر من 23000 عينة واختبار النماذج على مجموعة الاختبار الأصلية حيث كنا قد اختبرنا النماذج بواسطة مجموعة الاختبار المعززة في دراستنا السابقة. كما أننا في هذه الدراسة نطبق تقنيات نسبة البيانات لدراسة تأثير حجم مجموعة البيانات. ونقوم في جميع التجارب بمقارنة أداء نماذج (AraT5) الأساسية و(Arat5 v2) و(mT5).
المنهجية
سنحدد في هذا القسم المنهجية المستخدمة لتحسين الترجمة من النص العربي إلى النص الإشاري. ويركز نهجنا على توسيع حجم مجموعة البيانات بشكل كبير من خلال تقنيات مختلفة لزيادة البيانات وتنفيذ نماذج الترجمة الآلية المتقدمة. نحن نهدف إلى معالجة قيود الأنظمة السابقة القائمة على القواعد وتحسين دقة الترجمة وموثوقيتها من خلال إثراء مجموعة البيانات والاستفادة من نماذج “تسلسل إلى تسلسل”.
يوضح الشكل 1 مثالاً لعملية الترجمة من اللغة العربية المنطوقة إلى لغة الإشارة بما يشمل التمثيل الإشاري الوسيط والذي يعمل كخطوة حاسمة في سد الفجوة بين بناء الجملة في اللغة العربية المنطوقة وقواعد لغة الإشارة العربية. وستكون الترجمة الدقيقة بلغة الإشارة أسهل بالنسبة لنماذج الترجمة الآلية من خلال ترجمة اللغة المنطوقة إلى النص الإشاري.
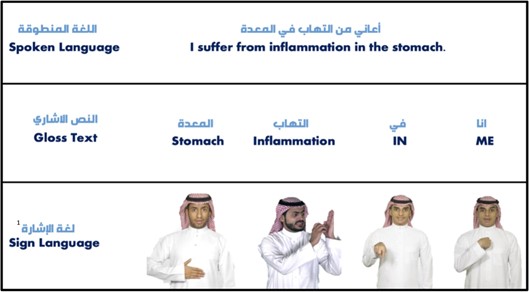
الشكل 1. توضيح لعملية الترجمة من اللغة العربية المنطوقة إلى النص الإشاري ثم إلى لغة الإشارة.
تقنيات زيادة البيانات
لقد قمنا باستخدام أساليب زيادة البيانات لتوسيع مجموعة البيانات لتصل إلى 23328 جملة بهدف تجاوز القيود التي فرضتها محدودية مجموعة بيانات لغة الإشارة العربية الأصلية والتي كانت تتألف من 600 جملة فقط وهي تركز في الغالب على مجال الرعاية الصحية. وتشمل تقنيات الزيادة الأساسية المستخدمة (BR) و(SR) و(SP). وقد تم اختيار هذه التقنيات بناءً على قدرتها على تعزيز تنوع وقوة بيانات التدريب وهو أمر ضروري للتعامل مع السمات اللغوية المعقدة للغة العربية ولغة الإشارة العربية.
يعد تطوير واستخدام خوارزمية الفهرسة أحد المكونات الأساسية لمنهجيتنا فهي تضمن المعالجة المنهجية والمطابقة الدقيقة بين النص العربي وما يقابله من النص الإشاري. وتقوم خوارزمية الفهرسة بتعيين مؤشرات فهرسة لكل كلمة في كل من الجمل العربية الأصلية وما يقابلها من النص الإشاري مع الحفاظ على المحاذاة والاتساق طوال عملية زيادة البيانات. ويعد هذا أمراً ضروريًا للحفاظ على المعنى الدلالي للجمل عند تطبيق تقنيات زيادة البيانات لأنه يضمن الانعكاس الدقيق لأي تعديلات يتم إجراؤها على النص الأصلي على نسخة النص الإشاري. ويسهل استخدام هذه الخوارزمية التكامل السلس لعينات البيانات الجديدة مما يسمح بزيادة البيانات بشكل فعال وقابل للتطوير ووضع الأساس لإنشاء مجموعة بيانات متنوعة وعالية الجودة.
استبدال الفراغات (BR): هو منهجية لزيادة البيانات تستخدم في معالجة اللغة الطبيعية لمحاكاة الكلمات المفقودة أو غير المعروفة وتعزيز أداء نماذج التعلم الآلي. وتتضمن هذه التقنية إخفاء كلمات محددة في الجملة والتنبؤ بهذه الكلمات بناءً على السياق المحيط باستخدام أداة ملء الفراغ ونموذج (AraELECTRA)[20]. وتتيح تقنية استبدال الفراغات إثراء مجموعة البيانات بما يصل إلى 21804 عينة جديدة من خلال إنشاء نسخ معدلة من الجمل الأصلية وتوليد كلمات مرشحة جديدة بدل الكلمات المخفية.
يقدم استبدال المرادفات (SR) تنوعًا معجميًا عن طريق استبدال الكلمات بمرادفاتها من قاموس محدد مسبقًا ما يؤدي بالتالي إلى زيادة تنوع المفردات مع الحفاظ على المعنى العام للجمل. وتستخدم هذه الطريقة قاموس مخصص بناءً على قاموس لغة الإشارة السعودية ومجموعة بيانات لغة الإشارة العربية مما يضمن كون المرادفات ذات صلة بلغة الإشارة العربية من حيث السياق. ومن خلال تعريض النموذج لاختيارات معجمية مختلفة تنقل معاني مماثلة تعزز هذه الطريقة قدرة النموذج على تغطية التعبيرات اللغوية المختلفة وتحسن قدرته على التكيف مع استخدامات الكلمات المختلفة مما أدى إلى إنشاء 684 جملة جديدة.
تُستخدم طريقة إعادة صياغة الجملة (SP) لتزويد بيانات التدريب ببعض التنوع ومساعدة النموذج على تعلم طرق مختلفة لتقديم نفس المعلومات من خلال إنشاء نسخ معاد صياغتها من الجمل من خلال الترجمة العكسية (أي ترجمة الجمل إلى الإنجليزية ثم إلى العربية مرة أخرى). وتولد هذه العملية عبارات بديلة تحافظ على المعنى الأصلي ولكنها تختلف من حيث البنية. ويعد هذا التنوع أمرًا بالغ الأهمية للتعامل مع الاختلافات البنيوية الكبيرة بين اللغة العربية ولغة الإشارة العربية. ويصبح النموذج من خلال التدريب على البيانات المعاد صياغتها أكثر مرونة في التعرف على مجموعة واسعة من بنى الجمل وترجمتها بدقة وبالتالي تتحسن قدرته على التقاط المعنى والحفاظ على الاتساق النحوي في الترجمة. وقد نتج عن استخدام طريقة إعادة صياغة الجملة 840 جملة جديدة.
يوضح الشكل 2 أمثلة لمجموعات من البيانات المعززة التي تغطي مجموعة واسعة من المفردات وبنى الجمل مما يوفر للنموذج الخبرة اللازمة للتعامل مع الفروق الدقيقة اللغوية.
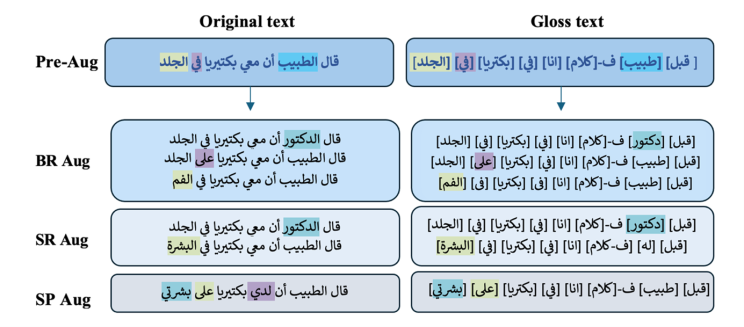
الشكل 2. عينات من مجموعات البيانات من اللغة العربية إلى النص الإشاري العربي
يعزز استخدام تقنيات زيادة البيانات كما هو مفصل في عملنا السابق بشكل كبير من حجم مجموعة البيانات وتنوعها [19]. وتوفر مجموعة البيانات الغنية هذه أساسًا متينًا لتدريب نماذج الترجمة الآلية الفعالة ودعم تطوير نظام قوي قادر على ترجمة النص العربي بدقة إلى لغة الإشارة العربية وتحسين إمكانية النفاذ والتواصل لمجتمع الصم.
نموذج الترجمة الآلية “تسلسل إلى تسلسل”
أصبحت نماذج المحولات “من تسلسل إلى تسلسل” تشكل حجر الزاوية في معالجة اللغة الطبيعية وخاصة للمهام التي تتطلب تحويل تسلسلات الإدخال إلى تسلسلات إخراج مثل الترجمة الآلية. وقد تم تصميم هذه النماذج للتعامل مع تسلسلات الإدخال والإخراج ذات الأطوال المتغيرة مما يجعلها مناسبة لترجمة النص من لغة إلى أخرى مع الحفاظ على معنى العينات. إن نموذج T5 (محول لتحويل النص إلى نص) هو أحد هذه النماذج المتطورة والذي يوحد مهام معالجة اللغة الطبيعية المختلفة تحت إطار واحد عن طريق تحويلها إلى مهام “نص إلى نص” [6]. وتعد هذه البنية مناسبة بشكل خاص لمهام الترجمة نظرًا لقدرتها على التعامل مع الأنماط اللغوية المتنوعة والسياق بشكل فعال.
نستخدم أيضًا في دراستنا (AraT5-V2) وهو أحد أشكال تدريب نموذج T5 مخصص للغة العربية [21]. ويستفيد (AraT5-V2) من البنية القوية لـ T5 والتي تم تطويرها للتعامل مع تعقيدات بناء الجملة والدلالات العربية. ويتكون النموذج من مُشفِّر ذي طبقات متعددة لكل منها آلية انتباه ذاتي و”شبكة تغذية للأمام” يتبعها مُفكِّك تشفير يتضمن أيضًا انتباهًا إلى مخرجات المُشفِّر. ويسمح هذا الهيكل للنموذج بإنشاء ترجمات تعكس بدقة معنى اللغة المصدر وتتوافق مع المعايير النحوية للغة الهدف. ويوضح الشكل 3 بنية الترجمة الآلية للمصطلحات العربية باستخدام نموذج (AraT5).
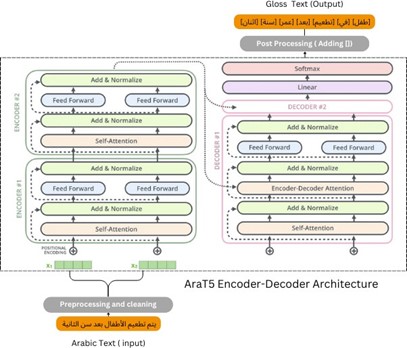
الشكل 3. بنية نموذج (AraT5) في الترجمة الآلية إلى النص الإشاري
كما هو موضح في الشكل 3 فإن عملية تدريب (AraT5-V2) لترجمة النص العربي إلى النص الإشاري تتضمن سلسلة من الخطوات المنظمة بعناية لتحسين أداء النموذج. بدايةً يقوم النموذج المدرب مسبقًا والذي يفهم بالفعل بنى اللغة العربية العامة بتدريب إضافي على مجموعة بيانات موازية من الجمل العربية وترجمتها الإشارية المقابلة.
ويقوم المشفر أثناء التدريب بمعالجة المدخلات وتحويلها إلى سلسلة من التمثيلات السياقية التي تغطي معنى الجملة. ثم يتم تمرير هذه التمثيلات إلى المشفر الذي يولد ناتج الشرح بطريقة تلقائية – يتنبأ برمز واحد في كل مرة مع الاستفادة من الرموز التي تم إنشاؤها مسبقًا في عملية التنبؤ بالرمز التالي. ويتم تعديل معلمات النموذج باستخدام الانتشار العكسي (backpropagation) حيث يتم تقليل الاختلافات بين جمل الإشارة المتوقعة وجمل الإشارة الفعلية باستخدام خوارزميات التحسين مثل (AdamW). كما يتم تدريب المعلمات الفائقة (عوامل التدريب) بما في ذلك معدل التعلم وحجم الدفعة لتحقيق الأداء الأمثل ويتم استخدام تقنيات مثل التوقف المبكر لمنع حدوث مشكلة عدم الكفاءة عند التعامل مع البيانات الجديدة (overfitting). ويُعتبر النموذج جاهزًا للاختبار بمجرد أن يؤدي أداءً مرضيًا وفق مجموعة التحقق.
إن تدريب نموذج (AraT5-V2) يجعله قادراً على أخذ جملة عربية كمدخل وتوليد ترجمة مناسبة لها إلى نص الإشارة. وتضمن بنية التشفير وفك التشفير محافظة المخرجات على المعنى الدلالي واتباعها للقواعد النحوية للغة الإشارة مما يعكس المعرفة المكتسبة أثناء التدريب. ويتم تقييم أداء النموذج باستخدام مقاييس مثل درجة (BLEU) والتي تقيس دقة الجمل المترجمة مقابل الإشارات البشرية.
النتائج التجريبية
لقد استخدمنا نموذج (AraT5 V2) في تجاربنا وهو نموذج ترجمة آلية عصبية متطور مصمم خصيصًا للنص العربي. وقمنا بتقييم نموذجين آخرين وهما (mT5) [22] وهو نموذج محول متعدد اللغات قادر على التعامل مع لغات مختلفة و (AraT5 Base) [21] وهو الإصدار الأساسي من (AraT5) والذي تم تصميمه خصيصًا للغة العربية ولكنه يفتقد للتحسينات الموجودة في الإصدار الثاني V2. كما أن مقياس التقييم الأساسي المستخدم في هذه التجارب هو درجة معيار التقييم ثنائي اللغة (BLEU) والتي تُستخدم عادةً في مهام الترجمة الآلية لتقييم جودة الترجمة. وبالإضافة إلى درجة (BLEU) نقوم أيضًا بقياس خسائر التحقق والاختبار ومقارنة تنبؤات النموذج بمجموعات الاختبار المرجعية. لقد تم إجراء التدريب باستخدام معدل التعلم التكيفي مع مُحسِّن (AdamW) جنبًا إلى جنب مع معدل فاقد 0.1 لمنع حدوث مشكلة عدم الكفاءة عند التعامل مع البيانات الجديدة. وقد استخدمنا حجم دفعة يتراوح من 8 إلى 128 مع تعديله بناءً على حجم مجموعة البيانات ومجدول معدل التعلم الخطي. وقد تم إجراء 22 عملية مرور محلية على كامل بيانات التدريب (epochs) مع إجراء التقييم وحفظ النموذج كل 500 خطوة لمراقبة التقدم ومنع حدوث مشكلة عدم الكفاءة عند التعامل مع البيانات الجديدة.
أداء تقنيات زيادة البيانات
لقد قمنا بحساب درجات (BLEU) لكل طريقة على حدة وذلك بهدف تقييم أداء نموذج (AraT5-V2) المدرب باستخدام طرق مختلفة لزيادة البيانات. حيث تم تقييم كل طريقة لزيادة البيانات باستخدام التحقق المقسم (validation split) أثناء التدريب بينما تم حساب درجات (BLEU) باستخدام مجموعة اختبار لغة الإشارة العربية الأصلية المكونة من 90 عينة لتحديد التأثير الكلي على عملية الترجمة. ويستعرض الجدول 1 نتائج نموذج (AraT5-V2) الخاصة بكل طريقة لزيادة البيانات جنبًا إلى جنب مع النتائج من مجموعة البيانات الأصلية قبل الزيادة.
الجدول 1. مقاييس أداء (AraT5-V2) لمختلف طرق زيادة البيانات
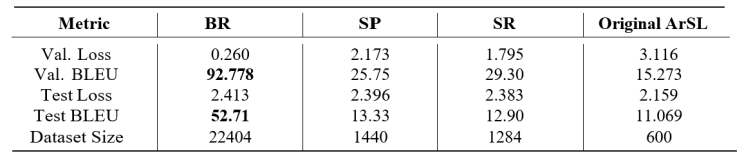
لقد استمرت طريقة (BR) كما هو موضح في الجدول 1 بتقديم أفضل أداء مع خسارة في التحقق من الصحة قدرها 0.260 ودرجة (BLEU) للتحقق من الصحة قدرها 92.778. وكانت درجة (BLEU) للاختبار ل(BR) 52.71 وهي أعلى بكثير من درجات الطرق الأخرى. من المحتمل أن يكون حجم مجموعة البيانات الكبير البالغ 22404 عينة لطريقة (BR) قد ساهم في أدائها المتفوق مما يسمح للنموذج بتعلم أنماط ترجمة أكثر قوة والتعامل بشكل فعال مع البيانات الجديدة عليه.
وفي المقابل أظهرت طريقتي (SP) و(SR) أداءً أضعف مع خسائر في التحقق من الصحة بلغت 2.173 و1.795 على التوالي ودرجات (BLEU) للتقييم 25.75 ل(SP) و29.30 ل(SR).أما طريقة (SR) التي استخدمت أصغر حجم لمجموعة البيانات والمكونة من 1284 عينة فقد كانت صاحبة أدنى درجة اختبار (BLEU) وهي 12.90. مما يشير إلى أن التغطية المحدودة للبيانات والمفردات قد قللت بشكل كبير من فعاليتها. ومع ذلك نرى أن طريقتي (SP) و(SR) تعملان بشكل أفضل من مجموعة بيانات لغة الإشارة العربية الأصلية غير المعززة والتي حصلت على درجة اختبار (BLEU) قدرها 11.069 مما يوضح قيمة تعزيز البيانات في تحسين جودة الترجمة.
لقد قمنا بدمج جميع طرق زيادة البيانات الثلاثة (BR وSP وSR) مما أدى إلى تكوين مجموعة بيانات من 23328 عينة تُستخدم لتدريب نموذج (AraT5 V2) ومقارنتها بنماذج (AraT5 Base) و(mT5) باستخدام مجموعة البيانات المعززة المختلطة. ومن المهم هنا ملاحظة أننا استخدمنا مجموعة الاختبار الأصلية لتقييم النماذج.
يوضح الجدول 2 نتائج مقارنة هذه النماذج. وكما هو موضح في الجدول 2 فقد حقق (AraT5 V2) أعلى درجات (BLEU) وأقل خسائر في مجال التحقق والاختبار مع درجة (BLEU) للتحقق من الصحة 86.16 ودرجة (BLEU) للاختبار 69.41. كما حقق النموذج الأساسي أداءً جيدًا من حيث درجة (BLEU) للتحقق من الصحة حيث وصل إلى 35.190 ولكنه حصل على درجة (BLEU) للاختبار أقل بكثير وهي 33.62. كما أظهر نموذج (mT5) أداءً معتدلاً مع درجة (BLEU) للتحقق من الصحة 72.380 ودرجة (BLEU) للاختبار أقل بكثير 15.157.
الجدول 2. مقارنة بين نماذج الترجمة الآلية المختلفة

نتائج نسب زيادة البيانات
بهدف التحقق من تأثير زيادة البيانات على أداء نموذج الترجمة الآلية الخاص بنا قمنا بإجراء تجربة على نسب زيادة البيانات. وتبحث هذه الدراسة في كيفية تأثير تغيير نسب البيانات المعززة على وجه التحديد 20٪ و 40٪ و 80٪ و 100٪ على دقة ترجمة نموذج (AraT5 V2). وتهدف هذه التجربة إلى تحديد التوازن الأمثل بين تنوع البيانات وحجمها لتحسين أداء النموذج وذلك من خلال ضبط كمية البيانات المعززة بشكل منهجي مع الحفاظ على إعدادات التدريب. وسيتم تقييم فعالية هذه النسب باستخدام درجات (BLEU) مما يوفر معلومات حول كيفية مساهمة مستويات مختلفة من زيادة البيانات في قوة ودقة نماذج الترجمة. ويوضح الجدول 3 حجم نسب البيانات لمختلف طرق زيادة البيانات.
الجدول 3. نسبة البيانات وأحجام مجموعات البيانات في مختلف طرق زيادة البيانات
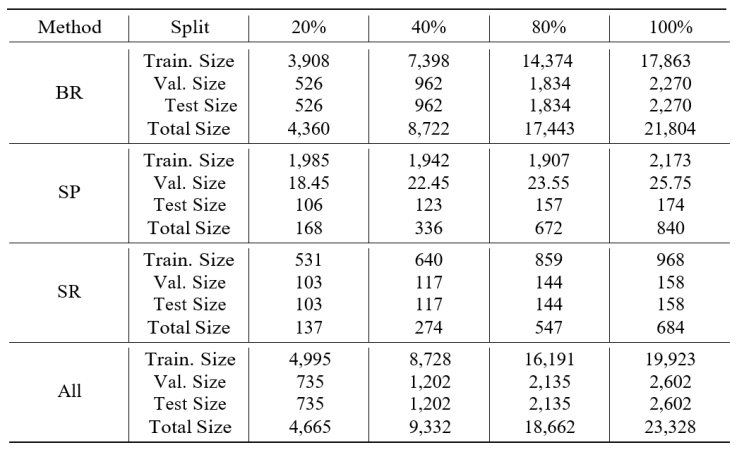
يوضح الجدول 3 أحجام مجموعات البيانات لمختلف طرق زيادة البيانات المختلفة بما في ذلك (BR وSP وSR) بشكل منفصل وبشكل جماعي بنسب 20% و40% و80% و100%. ويمثل الحجم الإجمالي عدد العينات المقابلة لكل نسبة من مجموعة البيانات الكاملة. وقد تم تحديد أحجام التحقق والاختبار من خلال تقسيم مجموعة البيانات الإجمالية وتضمين 90 عينة إضافية من مجموعة بيانات لغة الإشارة العربية الأصلية في مجموعة الاختبار.
إن هذا النهج يضمن إمكانية تقييم تأثير كل طريقة في ظل ظروف موحدة مما يوفر معلومات حول فعالية أحجام البيانات المختلفة واستخدامها معاً على دقة الترجمة. ويوضح الجدول 4 نتائج اختبار (BLEU) لكل طريقة زيادة بيانات والنسب المستخدمة.
الجدول 4. درجات اختبار (BLEU) لمختلف طرق ونسب زيادة البيانات
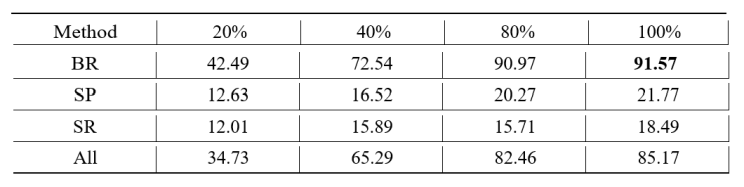
لقد تفوقت طريقة (BR) على الطرق الأخرى في جميع النسب كما هو موضح في الجدول 4 حيث حققت أعلى درجة اختبار (BLEU) وهي 91.57 بنسبة 100%. ويشير هذا التفوق إلى أن طريقة (BR) توفر بيانات التدريب الأكثر قوة للنموذج ويرجع ذلك على الأرجح إلى قدرتها على التعامل مع أنماط لغوية متنوعة بشكل فعال. وحتى في النسب المنخفضة فقد أظهرت طريقة (BR) تحسينات كبيرة مع درجة (BLEU) تبلغ 42.49 بنسبة زيادة 20% مما يسلط الضوء على تأثيرها القوي حتى مع وجود بيانات أقل.
أما طريقتا (SP وSR) فقد حققتا درجات (BLEU) اختبارية أقل نسبيًا في جميع النسب حيث حققت طريقة (SP) أعلى درجة (BLEU) بنسبة 21.77% عند زيادة 100% وبلغت طريقة (SR) ذروتها عند 18.4%. وتشير هذه النتائج إلى أنه في حين تساهم (SP وSR) في تحسين أداء النموذج إلا أن تأثيرهما أقل وضوحًا مقارنة بـ(BR). وقد يعود انخفاض فعالية (SP) إلى القيود المتأصلة في الترجمة العكسية والتي تنتج أحيانًا عبارات معاد صياغتها تشبه إلى حد كبير الأصل أو تسبب ضوضاء لا تعزز عملية التدريب. ويمكن أن يُعزى الأداء الضعيف نسبيًا ل(SR) إلى التغطية المحدودة للمفردات وأهمية السياق لقاموس المرادفات المستخدم والذي ربما أدى إلى استبدالات لم تغير بيانات التدريب بشكل كبير أو في بعض الحالات شوهت معنى الجملة.
لقد أظهر الاستخدام الجماعي لطرق زيادة البيانات (جميع الطرق) أداءً متوازنًا حيث حقق درجة اختبار (BLEU) بنسبة 85.17% عند زيادة بنسبة 100% مما يشير إلى أن مزيجًا من تقنيات الزيادة يمكن أن يقدم أداء جيداً ولكنه قد لا يتجاوز فعالية طريقة (BR) لوحدها. وبشكل عام تؤكد هذه النتائج على أهمية اختيار طرق زيادة البيانات المناسبة وتحسين تنفيذها لتعزيز دقة الترجمة الآلية فضلاً عن الحاجة إلى مقاربات أكثر تطورًا لتحسين طريقتي (SP وSR).
الخاتمة
لقد قمنا في هذه الدراسة بتعزيز ترجمة النص العربي إلى نص إشاري عربي باستخدام تقنيات زيادة البيانات المتقدمة ونموذج (AraT5 V2). وقد أظهرت نتائجنا أن طريقة استبدال الفراغات (BR) كانت صاحبة أعلى دقة في الترجمة في حين أن طريقة التكبير المختلطة حسنت الأداء أيضًا ولكنها لم تتفوق على (BR). ومع ذلك فقد استخدمنا في هذه الدراسة مجموعة بيانات صغيرة تم تطويرها في مجال الصحة والتي لا تغطي مجموعة شائعة من الكلمات العربية. وسيركز العمل المستقبلي على إكمال المرحلة الثانية لترجمة النص الإشاري إلى نص ثم إلى حركات لغة الإشارة العربية مما يؤدي إلى تطوير أنظمة ترجمة لغة الإشارة لتصبح أكثر كفاءة ودقة في خدمة مجتمع الصم الناطقين باللغة العربية بشكل أفضل.
المراجع
[1] Kushalnagar, R. (2019). Deafness and hearing loss. Web accessibility: A foundation for research, pages 35–47.
[2] Luqman, H., Mahmoud, S. A., et al. (2017). Transform-based arabic sign language recognition. Procedia Computer Science, 117:2–9.
[3] Al-Fityani, K. and Padden, C. (2010). Sign language geography in the arab world. Sign languages: A Cambridge survey, 20.
[4] Luqman, H. and Mahmoud, S. A. (2019). Automatic translation of arabic text-to-arabic sign language. Universal Access in the Information Society, 18(4):939–951.
[5] Koehn, P. and Knowles, R. (2017). Six challenges for neural machine translation. arXiv preprint arXiv:1706.03872.
[6] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67.
[7] Sidig, A. a. I., Luqman, H., and Mahmoud, S. A. (2018). Arabic sign language recog- nition using optical flow-based features and hmm. In Recent Trends in Information and Communication Technology: Proceedings of the 2nd International Conference of Reliable Information and Communication Technology (IRICT 2017), pages 297–305. Springer.
[8] Zhao, L., Kipper, K., Schuler, W., Vogler, C., Badler, N., and Palmer, M. (2000). A machine translation system from english to american sign language. In Envisioning Machine Translation in the Information Future: 4th Conference of the Association for Machine Translation in the Americas, AMTA 2000 Cuernavaca, Mexico, October 10–14, 2000 Proceedings 4, pages 54–67. Springer.
[9] Marshall, I. and Sáfár, É. (2003). A prototype text to british sign language (bsl) trans- lation system. In The companion volume to the proceedings of 41st annual meeting of the association for computational linguistics, pages 113–116.
[10] Almasoud, A. M. and Al-Khalifa, H. S. (2012). Semsignwriting: A proposed semantic system for arabic text-to-signwriting translation.
[11] Almohimeed, A., Wald, M., and Damper, R. I. (2011). Arabic text to arabic sign language translation system for the deaf and hearing-impaired community. In Proceedings of the second workshop on speech and language processing for assistive technologies, pages 101–109.
[12] El, A., El, M., and El Atawy, S. (2014). Intelligent arabic text to arabic sign language translation for easy deaf communication. International Journal of Computer Applica- tions, 92(8).
[13] Al-Rikabi, S. and Hafner, V. (2011). A humanoid robot as a translator from text to sign language. In 5th Language and Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics (LTC 2011), pages 375–379.
[14] Othman, A., Dhouib, A., Chalghoumi, H., Elghoul, O., and Al-Mutawaa, A. (2024). The acceptance of culturally adapted signing avatars among deaf and hard-of-hearing individuals. IEEE Access.
[15] Othman, A., El Ghoul, O., Aziz, M., Chemnad, K., Sedrati, S., and Dhouib, A. (2023). Jumla-qsl-22: Creation and annotation of a qatari sign language corpus for sign lan- guage processing. In Proceedings of the 16th International Conference on PErvasive Technologies Related to Assistive Environments, pages 686–692.
[16] Angelova, G., Avramidis, E., and Möller, S. (2022). Using neural machine translation methods for sign language translation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, pages 273–284.
[17] Jang, J. Y., Park, H.-M., Shin, S., Shin, S., Yoon, B., and Gweon, G. (2022). Automatic gloss-level data augmentation for sign language translation. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 6808–6813.
[18] Kayahan, D. and Güngör, T. (2019). A hybrid translation system from turkish spo- ken language to turkish sign language. In 2019 IEEE International Symposium on INnovations in Intelligent SysTems and Applications (INISTA), pages 1–6. IEEE.
[19] Alghamdi, D., Alsulaiman, M., Alohali, Y., Bencherif, M. A., and Algabri, M. (2024). Arabic gloss machine translation through data augmentation. In Proceedings of the Third SmartTech Conference (Manuscript submitted for publication). King Saud Uni- versity.
[20] Antoun, W., Baly, F., and Hajj, H. (2020). Araelectra: Pre-training text discriminators for arabic language understanding. arXiv preprint arXiv:2012.15516.
[21] Nagoudi, E. M. B., Elmadany, A., and Abdul-Mageed, M. (2021). Arat5: Text-to-text transformers for arabic language generation. arXiv preprint arXiv:2109.12068.
[22] Xue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., Barua, A., and Raffel, C. (2020). mt5: A massively multilingual pre-trained text-to-text transformer. arXiv preprint arXiv:2010.11934.