الكشف المبكر عن اضطراب طيف التوحد (ASD) لدى الأطفال باستخدام التعلم الآلي
ورقة علمية  وصول مفتوح |
متاح بتاريخ:27 أبريل, 2025 |
آخر تعديل:27 أبريل, 2025
وصول مفتوح |
متاح بتاريخ:27 أبريل, 2025 |
آخر تعديل:27 أبريل, 2025
الملخص:
يعتبر اضطراب طيف التوحد (ASD) حالة عصبية نمائية معقدة تؤثر على التواصل والتفاعل الاجتماعي والسلوك مما يستلزم التشخيص المبكر لهذه الحالة للتدخل الفعال. ويهدف هذا البحث إلى تحسين دقة وفعالية الكشف عن اضطراب طيف التوحد عند الأطفال الصغار من خلال تطبيق نماذج التعلم الآلي باستخدام مجموعة بيانات (Q-CHAT-10). وبعد اتباع منهجية ((CRISP-DM، قمنا بإجراء تحضير شامل للبيانات وتحديد الميزات وتقييم النموذج المستخدم. كما قمنا بمقارنة أداء ثلاثة نماذج للتعلم الآلي: الانحدار اللوجستي، وشجرة القرار (Decision Tree)، والشبكة العصبية الاصطناعية (ANN) . وقد أظهرت الشبكة العصبية الاصطناعية أعلى أداء حيث حققت نسبة دقة 98.5٪ ودرجة F1 ( (F1-Score بنسبة 98.5٪ تليها عن كثب نموذج شجرة القرار بدقة 98.23٪. وعلى الرغم من تحقيقه نسبة الدقة الأقل فقد حافظ الانحدار اللوجستي على أداء موثوق به بدرجة F1 تبلغ 91.02٪. ويسلط هذا البحث الضوء على إمكانات أدوات ما قبل التشخيص المدعومة بالذكاء الاصطناعي لتسريع عمليات الكشف عن اضطراب طيف التوحد مما يقلل بشكل كبير من أوقات الانتظار للتقييم. وسيركز العمل المستقبلي على دمج مجموعات البيانات السريرية واستكشاف البيانات متعددة الوسائط بما في ذلك تتبع حركة العين وتحليل الفيديو السلوكي لزيادة دقة التشخيص ودعم استراتيجيات التدخل المبكر في بيئات العالم الحقيقي.
الكلمات الرئيسية: اضطراب طيف التوحد؛ التعلم الآلي؛ الذكاء الاصطناعي؛ شجرة القرار؛ الغابة العشوائية؛ الانحدار اللوجستي.
المقدمة
يعتبر اضطراب طيف التوحد (ASD) حالة نمائية عصبية تؤثر على كيفية إدراك الأفراد لبيئتهم والتفاعل الاجتماعي. ويتسم هذا الاضطراب بصعوبات في الاتصال والتفاعلات الاجتماعية وأنماط السلوك المتكررة [1]. وعلى الرغم من اختلاف معدلات انتشاره باختلاف الدراسات والمناطق إلا أنه من المعتقد أن 1 من كل 100 شخص على مستوى العالم تقريبا قد تأثر باضطراب طيف التوحد [2]. وفي حين أن لا تزال الأسباب الدقيقة غير واضحة تشير الأبحاث إلى مجموعة من العوامل الوراثية والبيئية التي تلعب دورا في بدايته [3].
وقد ارتفع معدل تشخيص اضطراب طيف التوحد في المملكة المتحدة بين عامي 1998 و2018 بشكل كبير وخاصة بين البالغين والإناث. ومع ذلك لم يتحقق تقدم يذكر في زيادة التشخيص المبكر خلال مرحلة الطفولة على الرغم من الجهود المبذولة لاكتشاف الحالات قبل سن الثالثة [4]. ويعد الكشف المبكر عن اضطراب طيف التوحد أمرا بالغ الأهمية حيث تظهر الدراسات أن التدخلات تكون أكثر فعالية عندما يتم تنفيذها قبل أن يبلغ الطفل الثامنة [5]. كما ثبت أن العلاج السلوكي المكثف في مرحلة الطفولة المبكرة يعزز بشكل كبير القدرات المعرفية وتطوير اللغة والمهارات الاجتماعية لدى الأطفال ذوي اضطراب طيف التوحد في سن ما قبل المدرسة [6]. ويمكن أن يصل وقت الانتظار لإجراء تقييم أولي لحالة اضطراب طيف التوحد في المملكة المتحدة إلى 14 شهرا [1]. ففي ديسمبر 2022 كان هناك حوالي 140،000 شخص ينتظرون مواعيدهم. وتعد عملية التشخيص ضرورية للأطفال كي يحصلوا على الدعم والموارد اللازمة. على سبيل المثال، يمكن أن يساعد تشخيص اضطراب طيف التوحد الأسر على فهم الاحتياجات الخاصة لأطفالهم بشكل أفضل وضمان الحصول على الدعم التعليمي المخصص مثل خطط التعليم الفردي (IEPs) والمساعدة الإضافية في المدارس [7]. وغالبا ما يتطلب التشخيص نهجا تعاونيا يشمل تخصصات متعددة نظراً للطبيعة المعقدة والمتنوعة لاضطراب طيف التوحد. وقد تشمل هذه العملية بالنسبة للأطفال إجراء مقابلات مع الوالدين وملاحظات على السلوك والاختبارات المعرفية والتقييمات الطبية [8]. ومع ذلك فإن الأصول غير الواضحة لاضطراب طيف التوحد والإجراءات التشخيصية المطولة تجعل التشخيص الدقيق وفي الوقت المناسب أمراً صعباً. وغالبا ما تنطوي الأساليب الحالية على مراقبة مطولة وتقييمات شاملة في مختلف المجالات [9]. كما تشمل أدوات التشخيص الشائعة المقابلة التشخيصية المنقحة للتوحد (ADI-R) وجدول مراقبة تشخيص التوحد (ADOS) [10]. وتعتمد المقابلة التشخيصية المنقحة للتوحد على مقابلات شبه منظمة مع مقدمي الرعاية أو الوالدين [11] في حين يقوم جدول مراقبة تشخيص التوحد بتقييم السلوكيات من خلال أنشطة اللعب الخاصة شبه الهيكلية [12]. وللمساعدة في تقليل أوقات الانتظار لتقييم اضطراب طيف التوحد السريرية وتسهيل التشخيص المبكر للأطفال يتم استخدام أدوات الفحص قبل التشخيص بشكل متكرر لدعم عمليات الإحالة. وعادة ما تتضمن هذه الأدوات استبيانات موحدة يمكن أن يجيب عليها الآباء أو مقدمو الرعاية للأطفال أو يجريها الكبار بأنفسهم [13]. إن تعزيز عملية التشخيص أمر ضروري لضمان توفير التدخل المبكر والدعم الضروري للأفراد المصابين باضطراب طيف التوحد. ويمكن للتقييمات المبسطة أن تحسن إلى حد كبير من النتائج التنموية لذوي اضطراب طيف التوحد.
المواد والمنهجيات
تم في هذه الورقة البحثية استخدام منهجية العملية المعيارية متعددة القطاعات لاستخراج البيانات (CRISP-DM) لتقييم دقة الكشف المبكر عن اضطراب طيف التوحد باستخدام تقنيات مختلفة للتعلم الآلي.
![Phases of CRISP-DM [14]](https://cdn.nafath.mada.org.qa/data/wp-content/uploads/2025/04/28_3_1.png)
الشكل 1. مراحل العملية المعيارية متعددة القطاعات لاستخراج البيانات [14]
فهم البيانات
تم أخذ البيانات من (Kaggle) وتسمى باسم “بيانات فحص اضطراب طيف التوحد للأطفال الصغار”. وتقدم (Kaggle) مجموعة بيانات جديدة تركز على فحص التوحد عند الأطفال الصغار وهي تتضمن الميزات الرئيسية التي يمكن الاستفادة منها في التحليل المتقدم لا سيما في تحديد سمات التوحد وتعزيز تصنيف حالات اضطراب طيف التوحد. وتلتقط مجموعة البيانات هذه عشرة مؤشرات سلوكية (Q-Chat-10) إلى جانب الخصائص الفردية الإضافية التي ثبت أنها تميز بشكل فعال حالات اضطراب طيف التوحد عن الضوابط في دراسات العلوم السلوكية. إن مجموعة البيانات هي تنبؤية ووصفية بطبيعتها وتحتوي على أنواع بيانات اسمية/فئوية وثنائية ومستمرة مما يجعلها مناسبة لمهام التصنيف بالإضافة إلى التجميع أو تحليل الارتباط أو تقييم الميزات. وهي تنتمي لمجال العلوم الطبية والصحية والاجتماعية وتتكون من 1,054 حالة مع 18 سمة بما في ذلك متغير الفئة ولا تحتوي على أي قيم مفقودة. وتتضمن السمات عشرة عناصر سلوكية من استبيان (Q-Chat-10) (A1-A10)حيث تم تعيين الاستجابات إلى قيم ثنائية (“1” أو “0”). وبالنسبة للأسئلة من A1 إلى A9 فقد تم تعيين إجابات “أحيانًا” أو “نادرًا” أو “أبدًا” بالقيمة “1” بينما بالنسبة للسؤال A10 فقد تم تعيين إجابات “دائمًا” أو “عادة” أو “أحيانًا” “1.” وإذا تجاوزت النتيجة الإجمالية لجميع الأسئلة العشرة 3 فسيتم تشخيص الفرد على أنه من المحتمل أن يظهر سمات اضطراب طيف التوحد وبخلاف ذلك لم يتم تحديد أي سمات لاضطراب طيف التوحد. كما تم جمع الميزات الإضافية في مجموعة البيانات من خلال شاشة “إرسال” في تطبيق اختبارات اضطراب طيف التوحد مع تعيين متغير الفئة تلقائيًا بناءً على درجة المستخدم أثناء عملية الفحص. [15].
تحليل البيانات التوضيحية
تم إجراء تحليل البيانات التوضيحية (EDA) على مجموعة البيانات لاستكشاف السمات والأنماط الرئيسية المرتبطة باضطراب طيف التوحد (ASD) لدى الأطفال الصغار. وتشير النتائج إلى أن ما يقرب من 69.1% من الأطفال الصغار في جميع أنحاء العالم يعانون من اضطراب طيف التوحد. ولوحظ أكبر عدد من حالات اضطراب طيف التوحد بين الأوروبيين البيض يليهم الآسيويون في حين أظهرت المجموعات العرقية الهندية الأصلية وجماعات المحيط الهادئ قابلية أعلى للإصابة باضطراب طيف التوحد. كما تبين أن الذكور أكثر عرضة للإصابة باضطراب طيف التوحد مقارنة بالإناث. بالإضافة إلى ذلك فإن الأطفال الصغار الذين يعانون من اليرقان هم أكثر عرضة للإصابة باضطراب طيف التوحد من أقرانهم. ومن المثير للاهتمام أن غالبية الأطفال المصابين باضطراب طيف التوحد ليس لديهم أفراد من العائلة يعانون من هذه الحالة مما يشير إلى أن اضطراب طيف التوحد قد لا يكون وراثيًا في الغالب. ويتم إجراء اختبارات معظم حالات اضطراب طيف التوحد من قبل أفراد الأسرة. ويظهر الأطفال الصغار في الفئة العمرية 36 شهرًا أكبر عدد من تشخيصات اضطراب طيف التوحد. كما يكون احتمال الإصابة باضطراب طيف التوحد أكبر عند عمر عامين ويكون الأطفال الصغار الذين حصلوا على درجة (Q-Chat-10) أعلى من 3 أكثر عرضة لتشخيص اضطراب طيف التوحد. علاوة على ذلك فإن معظم الأطفال الصغار المصابين بالتوحد لا يتفاعلون عاطفيًا عندما ينزعج أحباؤهم مما يسلط الضوء على النقص الشائع في الاستجابة العاطفية بين هؤلاء الأطفال. وبهدف تصور هذه النتائج فقد تم إنشاء العديد من الرسوم البيانية والمخططات لتوضيح هذه الاتجاهات والأفكار بشكل أفضل.
إعداد البيانات
لم تكن هناك قيم مفقودة للميزات المحددة في مجموعة بيانات “الأطفال الصغار” مما يسمح باستخدام جميع العينات البالغ عددها 1054 في التدريب. ومع ذلك فإن كل من مجموعات بيانات الأطفال والمراهقين والبالغين تحتوي على قيم مفقودة تم تمثيلها بـ “؟” أو قيم تقع خارج النطاق المتوقع. وفد تم استبعاد 4 سجلات في مجموعة بيانات الأطفال والمراهقين بسبب عدم وجود قيم عمرية بينما تمت إزالة 46 سجلًا إضافيًا نظرًا لأنه تم وضع علامة “؟” على حقول “العلاقة” و”العرق” و” بلد الإقامة” فيها مما يشير إلى إما أنها غير مكتملة البيانات أو وجود أخطاء محتملة في عملية تعبئة النموذج. وعلى الرغم من عدم تضمين هذه الحقول في النموذج إلا أن الفجوات الكبيرة في البيانات تشير إلى أن هذه السجلات قد تكون غير صالحة للاستخدام. كما تم إزالة سجلين في مجموعة بيانات البالغين بسبب فقدان القيم العمرية وتم استبعاد سجل واحد ذكر فيه عمر “383” باعتباره قيمة متطرفة. علاوة على ذلك تم استبعاد 93 سجلًا بسبب عدم اكتمال حقول “العلاقة” و”العرق” و” بلد الإقامة ” مما أثار مخاوف بشأن صحة البيانات. وتتألف مجموعة بيانات الأطفال والمراهقون من 346 سجلاً بينما تحتوي مجموعة بيانات البالغين على 608 سجلاً. وبهدف توحيد البيانات تمت تسوية سمة العمر باستخدام (MinMaxScaler) مما أدى إلى قياس القيمة بين 0 و1. وبما أن جميع الميزات الأخرى كانت ثنائية فقد منع هذا التطبيع قيمة العمر من تشويه النموذج. وتم تقييم النماذج مع وبدون خطوة التطبيع هذه لتقييم تأثيرها على الأداء.
اختيار الميزة
تضمنت مجموعة البيانات الأولية 18 متغيرًا تم اختيار 15 منها لتدريب النموذج. وتم استبعاد المتغير “من أكمل الاختبار” لعدم ارتباطه بالنتيجة. وبعد توصية [15] تمت إزالة درجة (QCHAT-10) أيضًا نظرًا لاستخدامها لتعيين مسمى الفئة مما قد يؤدي إلى الإفراط في التجهيز. بالإضافة إلى ذلك تم حذف متغير “العرق” بسبب عدم توازنه في مجموعة البيانات مما قد يؤدي إلى تحيزات غير مقصودة. وتضمنت الميزات المتبقية المختارة للتدريب جميع عناصر
(Q -CHAT) العشرة بالإضافة إلى “العمر” و”الجنس” و”اليرقان” و”يوجد فرد من العائلة مصاب باضطراب طيف التوحد”. وكان المتغير الهدف هو متغير “الفئة”. وبغرض إعداد البيانات للتدريب تم ترميز متغيرات “الجنس” و”اليرقان” و”يوجد فرد من العائلة مصاب باضطراب طيف التوحد” و”الفئة” في أعداد صحيحة ثنائية باستخدام وظيفة “مشفر التسميات” (Label Encoder). وبالنسبة لمجموعات بيانات الأطفال والمراهقين والبالغين التي تم تنظيمها بشكل مماثل مع 20 ميزة فقد تم اختيار 13 منها للتدريب. وكما هو الحال في مجموعة بيانات الأطفال الصغار فقد تمت إزالة الميزات “العرق” و”بلد الإقامة” و”العلاقة”. وتم استبعاد ميزة “وصف العمر” لأنها كانت متطابقة عبر مجموعات البيانات (على سبيل المثال، “4-11 سنة” في مجموعة بيانات الأطفال). كما تم أيضًا تجاهل خاصيتي “النتيجة” و”التوحد” حيث تم استخدامهما لإنشاء متغير “الفئة”. وتم تحويل متغيرات “الجنس” و”اليرقان” و”الفئة” إلى أعداد صحيحة ثنائية باستخدام أداة تشفير التسميات لتحقيق الاتساق في تدريب النموذج.
النمذجة
تم استخدام ثلاثة نماذج للتنبؤ بدقة مجموعة بيانات اضطراب طيف التوحد: الانحدار اللوجستي وشجرة القرار (DT) والشبكة العصبية الاصطناعية (ANN). وقد تم تنفيذ النظام على (Google Colab 5) وهي بيئة تدوين الملاحظات (Jupyter) السحابية التي توفر الوصول إلى الموارد الحسابية بما في ذلك وحدات معالجة الرسومات. كما يسمح (Colab) بالتعاون السهل مما يجعله مفيدًا للمشاريع البحثية.
التقييم
يعد تقييم النموذج مرحلة حاسمة في التعلم القائم على الذكاء الاصطناعي مع التركيز على تقييم مدى جودة أداء النماذج المدربة. حيث تضمن هذه الخطوة تعميم النموذج بشكل فعال على البيانات الجديدة وتوجيه القرارات المتعلقة بالاستخدام وإجراء مزيد من التحسينات. وتساهم المقاييس والتقنيات التالية في إجراء تقييم شامل:
تقيس الدقة الأداء العام للنموذج من خلال إظهار عدد المرات التي يصنف فيها النتائج أو يتنبأ بها بشكل صحيح.
الدقة (Accuracy) = TP + TN / TP + TN + FP + FN
وتقيس الدقة (Precision) مدى دقة التنبؤات الإيجابية حيث تشير الدقة الأعلى إلى تصنيفات إيجابية أكثر صحة.
الدقة (Precision) = TP/ TP + FP
يقوم الاستدعاء بتقييم قدرة النموذج على اكتشاف الحالات الإيجابية الحقيقية. ويعني الاستدعاء الأعلى أن النموذج يحدد بشكل فعال الحالات الإيجابية الفعلية.
“التذكر” (Recall) = TP/ TP + FN
تجمع درجة F1 بين الدقة والتذكر في مقياس واحد عن طريق حساب متوسطهما التوافقي مما يوفر تقييمًا متوازنًا لكليهما.
درجة F1 = (2 × الدقة × التذكر) / (الدقة + التذكر)
F1- Score = (2 × precision × recall) / (precision + recall)
النتائج والمناقشة
الانحدار اللوجستي
يتم هنا تقييم نموذج الانحدار اللوجستي باستخدام بيانات التدريب والاختبار المحددة مسبقًا. وقد تم تكوين نموذج الانحدار اللوجستي باستخدام (max_iter=1000) لضمان التقارب أثناء عملية التحسين و(random_state=42) لقابلية التكرار. كما يتم تدريب النموذج على بيانات التدريب المتدرجة ويتم إجراء التنبؤات على مجموعة الاختبار. ويتم تقييم أداء النموذج باستخدام المقاييس الرئيسية بما في ذلك الدقة والتذكر ودرجة F1. كما يتم تنظيم هذه المقاييس في إطار بيانات (DataFrame) للمقارنة مع النماذج الأخرى. وبالإضافة إلى ذلك يتم تحليل سلوك التعلم للنموذج باستخدام منحنى التعلم. كما تقوم وظيفة منحنى التعلم (Learning_curve) من (scikit-Learn) بحساب دقة التدريب والتحقق من الصحة في مختلف أحجام مجموعات التدريب باستخدام التحقق المتبادل. وقد حقق النموذج دقة قدرها 90.4% وضبط (precision) 91.49% ودرجة تذكر أو استدعاء 90.56% ودرجة F1 91.02 %.
الشبكات العصبية الاصطناعية
تم تصميم نموذج الشبكة العصبية الاصطناعية (ANN) المطبق في هذا الكود للتصنيف الثنائي ببنية تتكون من طبقة مدخلات وطبقة مخفية واحدة وطبقة مخرجات. تحتوي طبقة المدخلات على 64 خلية عصبية وتستخدم الطبقة المخفية وظيفة تنشيط (ReLU) لإدخال اللاخطية. تستخدم طبقة المخرجات وظيفة (التفعيل) التنشيط السيني (Sigmoid activation) للتنبؤ باحتمالات النتائج الثنائية. وقد تم تجميع النموذج باستخدام مُحسِّن (Adam) ودالة فقدان الإنتروبيا الثنائية المتقاطعة والدقة كمقياس للتقييم. وبهدف منع الإفراط في التجهيز يتم استخدام خاصية (EarlyStopping) ومراقبة فاقد التحقق من الصحة وإيقاف التدريب مبكرًا إذا وصل أداء النموذج إلى أكثر من 10 فترات تحقق كاملة. وتستخدم عملية التدريب حجم دفعات يبلغ 20 بحد أقصى و100 فترة تحقق كاملة وتقسيم التحقق من الصحة بنسبة 20% لتقييم أداء النموذج على البيانات غير المرئية. وقد حقق النموذج دقة قدرها 98.5% وضبط (precision) 98.72% ودرجة استدعاء أو تذكر 98.46% ودرجة F1 98.05 %.
شجرة القرار
يتم هنا تقييم مصنف شجرة القرار باستخدام بيانات التدريب والاختبار المحددة مسبقًا. وقد تم تحسين نموذج شجرة القرار باستخدام معلمات تشعبية محددة مثل
(criterion=’entropy’, min_samples_split=10, min_samples_leaf=5) لتحسين عملية التعميم والتقليل من الإفراط في التجهيز. ويتم بعد التدريب إجراء التنبؤات على بيانات الاختبار وتقييم أداء النموذج باستخدام مقاييس مثل الدقة والضبط والاستدعاء “التذكر” ودرجة F1. ويتم تنظيم هذه المقاييس في إطار بيانات (DataFrame) للمقارنة مع النماذج الأخرى. كما يتم إجراء تحليل منحنى التعلم لتصور سلوك التعلم للنموذج. ويتم استخدام وظيفة منحنى التعلم من (scikit-Learn) لحساب دقة التدريب والتحقق لأحجام مختلفة من مجموعات التدريب. ثم يتم رسم المتوسطات والانحرافات المعيارية عبر طيات التحقق المتبادل لتحليل كيفية تعميم النموذج مع تقديم المزيد من البيانات. وقد حقق النموذج دقة قدرها 98.23%، وضبط (precision) 97%، ودرجة استدعاء أو تذكر 99% ودرجة F1 98 %.
مقارنة النتائج
الجدول 1. نتائج النموذج
| النموذج | الدقة | الضبط | الاستدعاء | F1-Score |
| شجرة القرار | 98.23% | 97% | 99% | 98% |
| الشبكة العصبية الاصطناعية | 98.5% | 98.72% | 98.46% | 98.5% |
| الانحدار اللوجستي
|
90.4% | 91.49% | 90.56% | 91.02% |
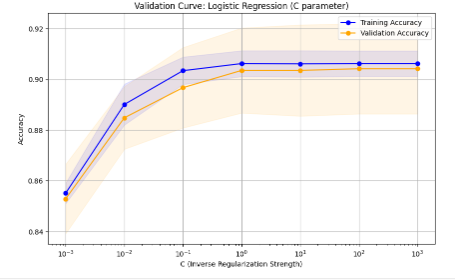
الشكل 2. منحنى التحقق من الانحدار اللوجستي
يمثل الرسم البياني منحنى التحقق من صحة الانحدار اللوجستي مما يوضح تأثير المعلمة C (قوة التنظيم “التضبيط” العكسي) على دقة النموذج لكل من مجموعات بيانات التدريب والتحقق من الصحة. وتشير القيم الأصغر لـ C على المحور السيني إلى تنظيم ” تضبيط ” أقوى مما يبسط النموذج بينما تقلل القيم الأكبر من مدى التنظيم ” التضبيط” مما يسمح للنموذج باكتشاف أنماط أكثر تعقيدًا. أما مع قيم C المنخفضة فتكون دقة التدريب والتحقق منخفضة بسبب نقص التجهيز حيث أن التنظيم المفرط يمنع النموذج من التعلم بفعالية. ومع زيادة C إلى نطاق معتدل يحقق النموذج توازنًا جيدا مع تحسين وتقارب دقة التدريب والتحقق من الصحة مما يؤشر على قابلية التعميم. ومع ذلك فإنه مع قيم C العالية جدًا تستمر دقة التدريب في الارتفاع لكن دقة التحقق من الصحة تنخفض مما يشير إلى الإفراط في التجهيز حيث يلتقط النموذج الضوضاء في بيانات التدريب ويفشل في التعميم. وتمثل المناطق المظللة التباين عبر طيات التحقق المتبادل. كما يوضح الرسم البياني أن قيمة C المثالية تقع في النطاق المتوسط حيث يحقق النموذج دقة عالية ومتوازنة في مجموعتي البيانات.
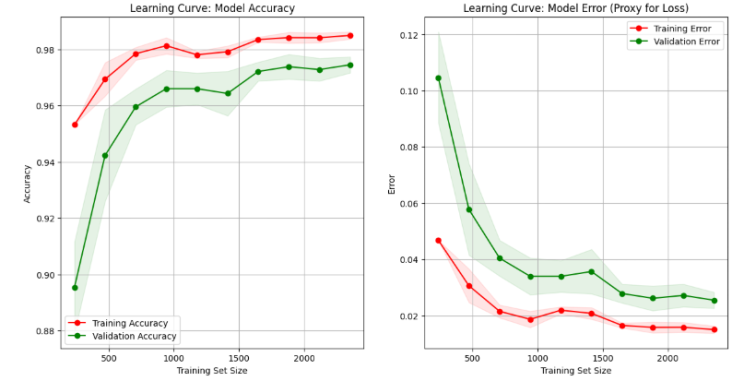
الشكل 3. منحنى التعلم لشجرة القرار
توضح منحنيات التعلم كيفية تطور دقة النموذج والخطأ فيه مع زيادة حجم مجموعة بيانات التدريب. ففي الرسم البياني للدقة تبدأ دقة التدريب بحيث تكون عالية جدًا عندما تكون مجموعة البيانات صغيرة لأن النموذج يحفظ البيانات. ومع ذلك تكون دقة التحقق أقل بكثير في هذه المرحلة بسبب سوء التعميم. ومع إضافة المزيد من البيانات تنخفض دقة التدريب قليلاً بينما تتحسن دقة التحقق باستمرار مع تقارب كلا المنحنيين واستقرارهما مع نمو مجموعة التدريب مما يشير إلى نموذج معمم بشكل جيد. وقد لوحظ العكس في الرسم البياني للأخطاء: حيث يكون خطأ التدريب منخفضًا جدًا في البداية بالنسبة لمجموعات البيانات الصغيرة ولكنه يزداد مع انتقال النموذج من الحفظ إلى التعميم. ويبدأ خطأ التحقق من الصحة مرتفعًا ولكنه يتناقص بشكل ملحوظ مع نمو مجموعة البيانات ويتقارب في النهاية مع خطأ التدريب عند مستوى منخفض. ويوضح هذا الأمر أن النموذج يعمل بشكل جيد على كل من البيانات المرئية وغير المرئية مما يحقق توازنًا جيدًا بين التحيز والتنوع.
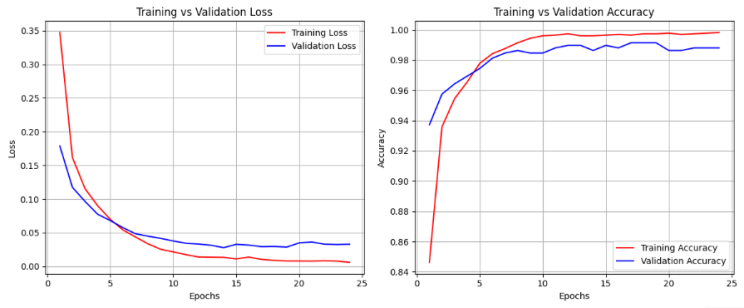
الشكل 4. منحنى التحقق من صحة الشبكة العصبية الاصطناعية
توضح الرسوم البيانية سلوك التعلم لنموذج الشبكة العصبية الاصطناعية (ANN) على مدى 25 فترة تحقق كاملة. ويُظهر المخطط الأيسر فاقد التدريب والتحقق من الصحة حيث يتناقص كلا المنحنيين بشكل مستمر خلال فترات التحقق المبكرة أثناء تطور تعلم النموذج. وينخفض فاقد التدريب (الأحمر) بسرعة ويتبع فاقد التحقق (الأزرق) اتجاهًا مشابهًا ويستقر في النهاية عند قيمة منخفضة. ويشير هذا الأمر إلى أن النموذج ليس مفرط التجهيز أو ناقص التجهيز مما يحقق درجة تعميم جيدة. وتجسد الحبكة الصحيحة دقة التدريب والتحقق من الصحة. وترتفع دقة التدريب (الأحمر) بسرعة وتقترب من 100%، في حين أن دقة التحقق (الأزرق) تزيد أيضًا وتستقر عند مستوى أقل قليلاً من دقة التدريب. وتشير الفجوة الصغيرة بين المنحنيين إلى أن النموذج يعمم بشكل جيد على البيانات غير المرئية دون الإفراط في التجهيز.
الخاتمة والتوجهات المستقبلية
لقد كان الهدف الأساسي لهذا المشروع هو الاستفادة من الذكاء الاصطناعي لإنشاء نهج فعال وشفاف لاكتشاف اضطراب طيف التوحد بهدف المساعدة في تقليل أوقات الانتظار للتشخيص. وقد أظهرت أساليب التعلم الآلي المطبقة أداءً جيدًا للكشف المبكر عن اضطراب طيف التوحد. حيث حققت الشبكة العصبية الاصطناعية (ANN) أعلى أداء إجمالي بدرجة F1 بلغت 98.5% في حين أظهر نموذج شجرة القرار أيضًا نتائج ممتازة. وعلى الرغم من أن نموذج الانحدار اللوجستي كان أقل فعالية من النموذجين الآخرين إلا أنه لا يزال يعمل بشكل موثوق مع درجة F1 تبلغ 91.02%. وينبغي أن تركز الخطوات التالية على تدريب النماذج باستخدام مجموعة بيانات متعددة الوسائط والتصنيفات السريرية والتعاون مع المتخصصين في الرعاية الصحية لمزيد من التطوير. كما أنه وبهدف تحسين الدقة يجب أن تركز الأبحاث المستقبلية على تطوير مجموعة بيانات تعتمد على الأفراد الذين خضعوا لتقييمات سريرية وتم تشخيصهم وفقًا لذلك. بالإضافة إلى ذلك فإنه يمكن للجمع بين أنواع مختلفة من البيانات مثل مقاطع الفيديو ومعلومات تتبع حركة العين أن يزيد من دقة عمل النموذج. وقد يكون التحسين المحتمل هو تطوير نماذج تتضمن بيانات متعددة الوسائط يمكنها أن تعزز الموضوعية وتقلل من التحيزات التي غالبًا ما تظهر في عملية اكتشاف وتشخيص اضطراب طيف التوحد.